Background
This assignment can be found here, and the starting code can be found in the pset3 directory here.
The goal is to implement functioning kernel virtual memory management, and use it to implement syscalls such as fork.
What we start off with is a basic kernel with example programs loaded in, along with a display that visualizes page tables:
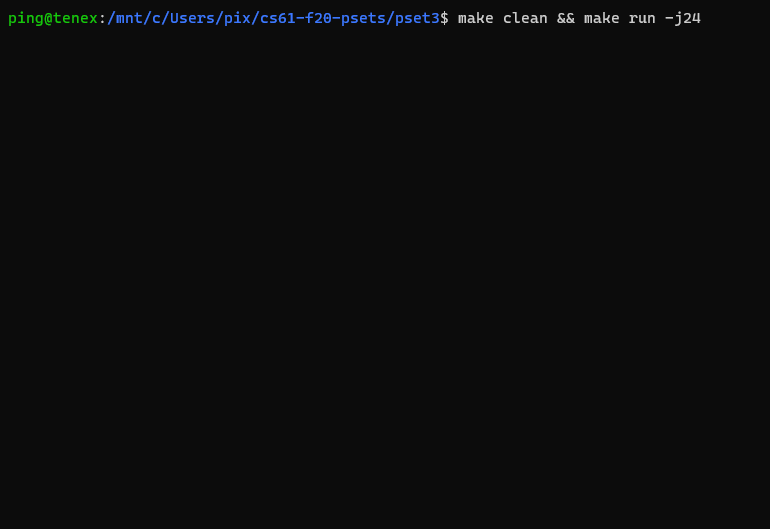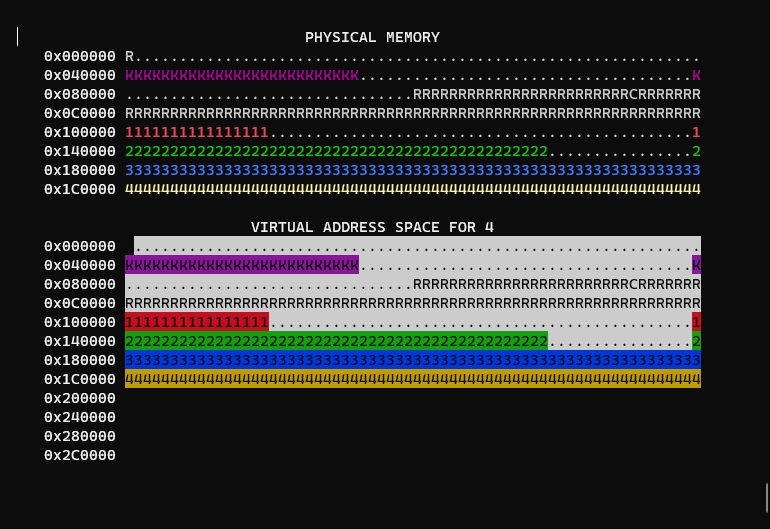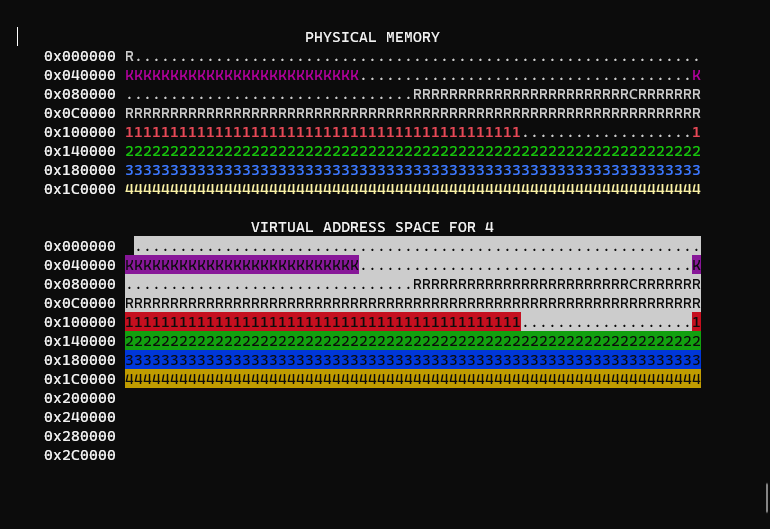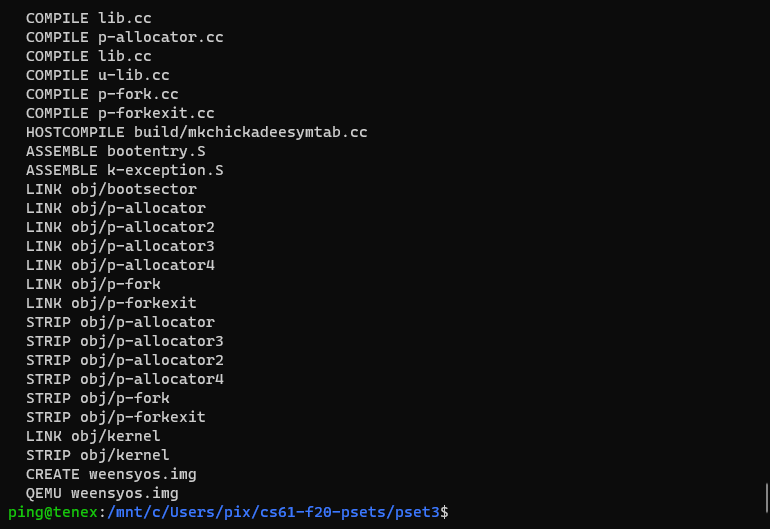
By default, WeensyOS spawns 4 programs which map pages sequentially until its memory is exhausted.
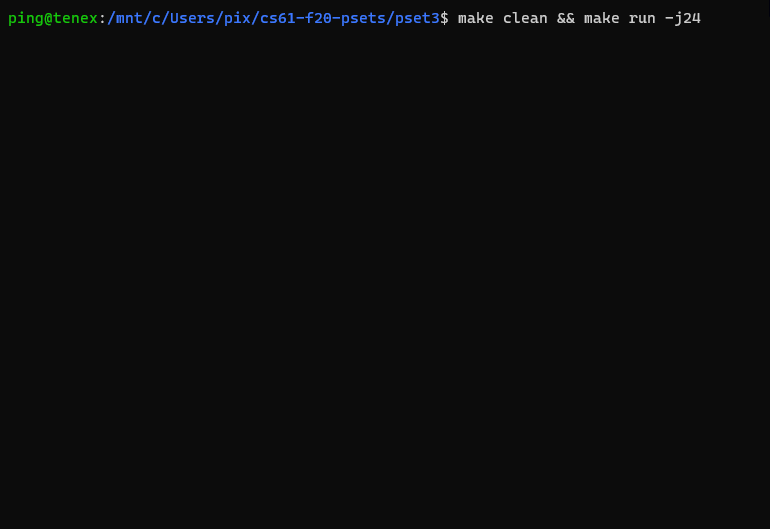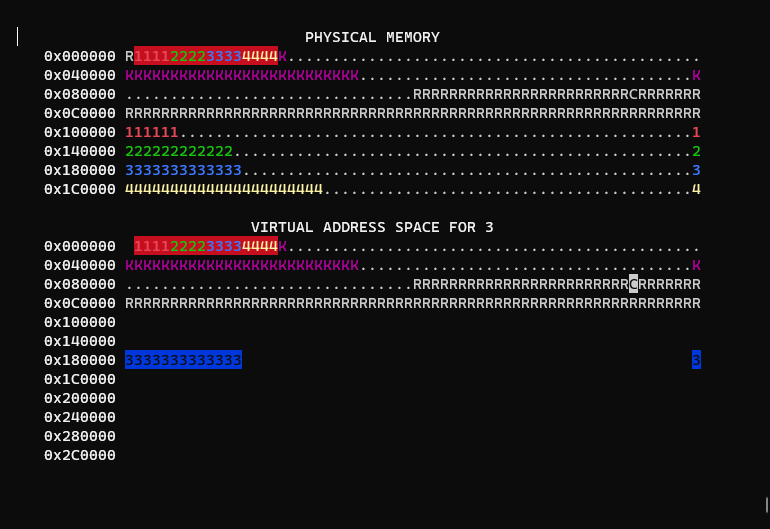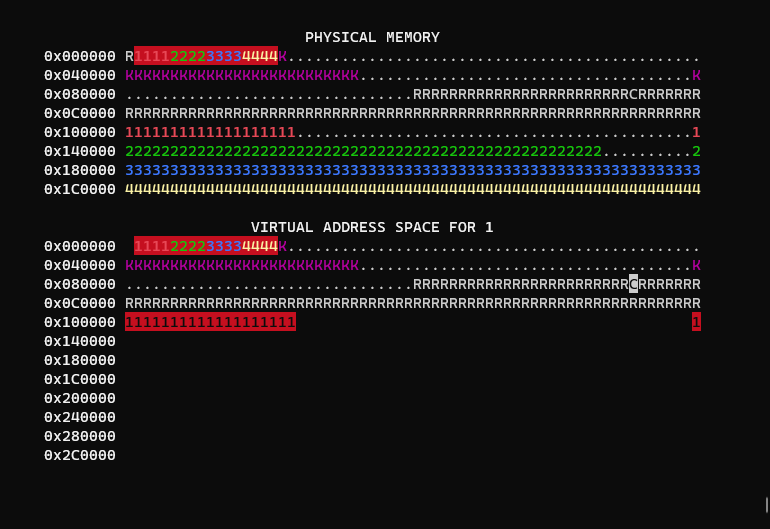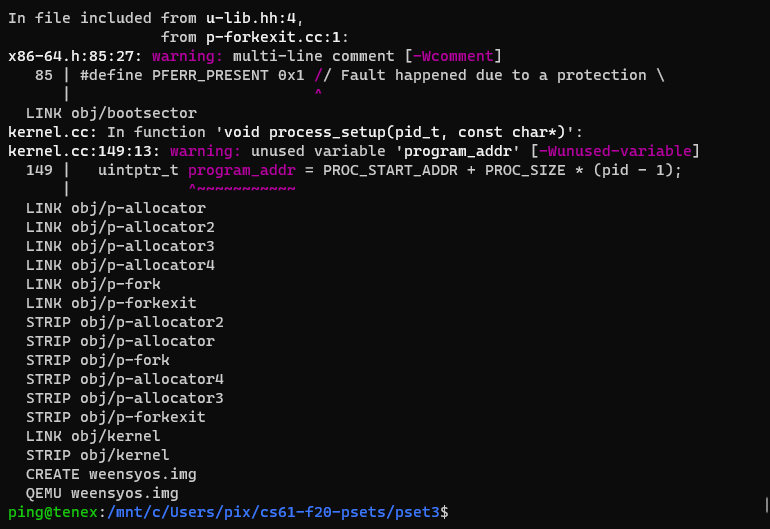
You may notice physical memory looks nearly identical to the virtual memory of each process. This is because there is also no isolation between processes or the kernel, aka an 'identity mapping'.
Kernel and process isolation
The first step of this assignment is to implement basic isolation between processes, preventing them from touching memory they shouldn't.
I chose the strategy of first applying default protections to the kernel's page table, then copying it it to each process:
void kernel_start(const char* command) {
...
// Initialize the kernel page table
for (vmiter it(kernel_pagetable); it.va() < MEMSIZE_VIRTUAL; it += PAGESIZE) {
if (it.va() != 0) {
int flags;
// Console and process memory should be user accessible
if (it.va() == CONSOLE_ADDR || it.va() >= PROC_START_ADDR) {
flags = PTE_P | PTE_W | PTE_U;
} else {
flags = PTE_P | PTE_W;
}
it.map(it.va(), flags);
} else {
it.map(it.va(), 0);
}
}
...
}
void process_setup(pid_t pid, const char* program_name) {
...
// Allocate a new page table
x86_64_pagetable* pagetable = kalloc_pagetable();
// Iterate both our new page table and the kernel page table
vmiter it2(pagetable);
for (vmiter it(kernel_pagetable); it.va() < MEMSIZE_VIRTUAL; it += PAGESIZE) {
// Copy 1:1 from kernel to process
it2.map(it.va(), it.perm());
it2 += PAGESIZE;
}
// Assign to the process, where it will be loaded by exception_return
ptable[pid].pagetable = pagetable;
...
}This gives us the desired isolation where processes can only read and write to their own memory:
Kernel page allocator
Processes are given dedicated space in physical memory (defined by PROC_START_ADDR), a limitation which prevents them from using more than PROC_SIZE bytes of memory.
First we need to implement a simple page allocator, I've chosen to implement an extremely simple free list.
How a free list works is that chunks of unallocated pages form a single-linked list:
struct free_page {
free_page* next;
};
extern free_page* next_free_page;To fill this list, we use allocatable_physical_address to check if a physical page is allocatable, pushing them all to the list in kernel_start:
free_page* next_free_page = nullptr;
void kernel_start(const char* command) {
...
// Set up page allocator
for (int i = NPAGES; i != 0; i--) {
uintptr_t kmem = (i - 1) * PAGESIZE;
if (allocatable_physical_address(kmem)) {
auto newPage = (free_page*)kmem;
newPage->next = next_free_page;
next_free_page = newPage;
}
pages[i - 1].refcount = 0;
}
...
}
kalloc and kfree now have a trivial implementation, pushing and popping from the list:
void* kalloc() {
if (next_free_page == nullptr) {
return nullptr;
} else {
free_page* page = next_free_page;
auto& info = pages[(uintptr_t)page / PAGESIZE];
assert(info.refcount == 0);
info.refcount = 1;
next_free_page = next_free_page->next;
return page;
}
}
void kfree(void* kptr) {
if (kptr == nullptr) return;
check_valid_kptr(kptr);
auto page = (free_page*)kptr;
auto& info = pages[(uintptr_t)page / PAGESIZE];
assert(info.refcount == 1);
info.refcount = 0;
page->next = next_free_page;
next_free_page = page;
}
The pages array provided by WeensyOS is how the memory viewer keeps track of physical pages, including a reference count:
struct pageinfo {
uint8_t refcount;
bool visited;
bool used() const { return this->refcount != 0; }
};This reference count is useful because multiple processes can share the same physical memory, whether it be from COW or read-only executable sections.
To facilitate reference counting I've made functions to acquire and release references to shared physical pages:
void kacquire(void* kptr) {
if (kptr == nullptr) return;
pageinfo& info = pages[(uintptr_t)kptr / PAGESIZE];
assert_gt(info.refcount, 0);
info.refcount++;
}
void krelease(void* kptr) {
if (kptr == nullptr) return;
pageinfo& info = pages[(uintptr_t)kptr / PAGESIZE];
assert_gt(info.refcount, 0);
if (info.refcount == 1) {
kfree(kptr);
} else {
info.refcount--;
}
}The kacquire function simply increments the reference count of the page, and krelease decrements it, freeing the page when it hits zero.
Virtual memory
In order to implement virtual memory we need to replace the primitive 1:1 page mapping with ones that takes pages from kalloc, but first we will add support for execution protection.
No-execute (NX) protection
This wasn't part of the assignment but I thought it was a cool feature to add.
Without NX protection all memory is executable, this is problematic as it makes buffer overflow exploits extremely powerful. To solve this security issue we will mark pages that do not contain code as not executable with the NX bit.
In several places WeensyOS mistakenly uses a 32 bit integer to store page protection flags, this truncates the top 32 bits that contain NX and some other useful OS flags.
The fix is fairly simple, just replace all of these instances of int with uint64_t:
-int vmiter::try_map(uintptr_t pa, int perm) {
+int vmiter::try_map(uintptr_t pa, uint64_t perm) {- inline void map(uintptr_t pa, int perm);
+ inline void map(uintptr_t pa, uint64_t perm);
- inline void map(void* kptr, int perm);
+ inline void map(void* kptr, uint64_t perm);
- [[gnu::warn_unused_result]] int try_map(uintptr_t pa, int perm);
- [[gnu::warn_unused_result]] inline int try_map(void* kptr, int perm);
+ [[gnu::warn_unused_result]] int try_map(uintptr_t pa, uint64_t perm);
+ [[gnu::warn_unused_result]] inline int try_map(void* kptr, uint64_t perm);
- int perm_;
+ uint64_t perm_;
- static constexpr int initial_perm = 0xFFF;
+ static constexpr uint64_t initial_perm = 0xFFE0000000000FFF;
-inline void vmiter::map(uintptr_t pa, int perm) {
+inline void vmiter::map(uintptr_t pa, uint64_t perm) {
-inline void vmiter::map(void* kp, int perm) {
+inline void vmiter::map(void* kp, uint64_t perm) {
-inline int vmiter::try_map(void* kp, int perm) {
+inline int vmiter::try_map(void* kp, uint64_t perm) {Some extra defines can be added to x86-64.h:
// More useful flags
#define PTE_PU 0x7UL // PTE_P | PTE_U
#define PTE_OS4 0x0020000000000000UL
#define PTE_OS5 0x0040000000000000UL
#define PTE_OS6 0x0080000000000000UL
#define PTE_OS7 0x0100000000000000UL
#define PTE_OS8 0x0200000000000000UL
#define PTE_OS9 0x0400000000000000UL
#define PTE_OS10 0x0800000000000000UL
#define PTE_OS12 0x1000000000000000UL
#define PTE_OS13 0x2000000000000000UL
#define PTE_OS14 0x4000000000000000UL
#define PTE_PXD 0x8000000000000001UL // PTE_P | PTE_XD
#define PTE_PUXD 0x8000000000000005UL // PTE_P | PTE_U | PTE_XD
#define PTE_PWXD 0x8000000000000003UL // PTE_P | PTE_W | PTE_XD
#define PTE_PWUXD 0x8000000000000007UL // PTE_P | PTE_W | PTE_U | PTE_XDIn order to track which segments of memory are executable, a few more modifications to the kernel and its linker script are necessary:
// Returns the start of the kernel rodata segment.
uintptr_t rodata_start_addr();
// Returns the start of the kernel (r/w) data segment.
uintptr_t data_start_addr();
// Returns the end of the kernel address space.
uintptr_t kernel_end_addr();
struct program_image_segment {
...
// Return true iff the segment is executable.
bool executable() const;
...
}// Make these offsets accessible to the rest of the kernel
uintptr_t rodata_start_addr() {
extern char _rodata_start[];
return (uintptr_t)_rodata_start;
}
uintptr_t data_start_addr() {
extern char _data_start[];
return (uintptr_t)_data_start;
}
uintptr_t kernel_end_addr() {
extern char _kernel_end[];
return (uintptr_t)_kernel_end;
}
bool allocatable_physical_address(uintptr_t pa) {
return !reserved_physical_address(pa)
&& (pa < KERNEL_START_ADDR || pa >= round_up(kernel_end_addr(), PAGESIZE))
&& (pa < KERNEL_STACK_TOP - PAGESIZE || pa >= KERNEL_STACK_TOP)
&& pa < MEMSIZE_PHYSICAL;
}
bool program_image_segment::executable() const {
return ph_->p_flags & ELF_PFLAG_EXEC;
} ...
. = ALIGN(4096);
_rodata_start = .; /* A tag to indicate the start of rodata */
.rodata : {
...Finally, execution protection can be enforced for the kernel in kernel_start:
void kernel_start(const char* command) {
...
// (re-)initialize kernel page table
for (vmiter it(kernel_pagetable); it.va() < MEMSIZE_PHYSICAL; it += PAGESIZE) {
if (it.va() != 0) {
uint64_t flags;
if (it.va() == CONSOLE_ADDR) {
// The console should be r/w to users
flags = PTE_PWUXD;
} else if (it.va() >= KERNEL_START_ADDR && it.va() < rodata_start_addr()) {
// The text segment should be read-only execute
flags = PTE_P;
} else if (it.va() >= rodata_start_addr() && it.va() < data_start_addr()) {
// The rodata segment should be read-only
flags = PTE_PXD;
} else {
// The rest (data segment, heap) should be r/w
flags = PTE_PWXD;
}
it.map(it.va(), flags);
} else {
// nullptr is inaccessible even to the kernel
it.map(it.va(), 0);
}
}
...
}To check if this actually works you can mark the text segment with the XD bit, WeensyOS will crash on startup because it's trying to execute memory that is now protected:
If the XD bit is cleared from the text segment, the OS continues running as normal, yay!
Process allocation
So far pages are manually mapped to a process from a few places, to make it simpler I've created a single function that takes care of allocation, mapping, copying, and dealing with edge cases:
static bool proc_alloc(pid_t pid, uintptr_t vaddr, size_t sz, uint64_t flags = PTE_PWUXD, void* src = nullptr) {
assert_eq(vaddr & PAGEOFFMASK, 0);
vmiter it(ptable[pid].pagetable);
uintptr_t num_pages = (sz + PAGESIZE - 1) / PAGESIZE;
for (uintptr_t page = 0; page < num_pages; page++) {
void* kptr = kalloc();
if (kptr != nullptr) {
it.find(vaddr + page * PAGESIZE);
if (it.try_map(kptr, flags) >= 0) {
// Success, copy from src and continue
if (src != nullptr) {
memcpy(kptr, (void*)src, min(sz, PAGESIZE));
src = (char*)src + PAGESIZE;
sz -= PAGESIZE;
}
continue;
} else {
kfree(kptr);
}
}
// Map or allocation failed, free and unmap everything
while (page > 1) {
page--;
it.find(vaddr + page * PAGESIZE);
kfree(it.kptr());
assert(it.perm() == flags);
it.map(it.pa(), PTE_XD);
}
return false;
}
return true;
}We can then use this function along with the program_image_segment::executable function defined earlier in process_setup to load ELF segments:
void process_setup(pid_t pid, const char* program_name) {
...
for (auto seg = pgm.begin(); seg != pgm.end(); seg++) {
if (seg.size() == 0) continue;
uint64_t flags = PTE_PUXD;
if (seg.writable()) {
flags |= PTE_W;
}
if (seg.executable()) {
flags &= ~PTE_XD;
}
// Allocate and copy segment to process
if (!proc_alloc(pid, seg.va(), seg.size(), flags, (void*)seg.data())) {
panic("Failed to allocate process memory during setup");
}
}
...
}Additionally the syscall_page_alloc function can use proc_alloc rather than mapping directly:
int syscall_page_alloc(uintptr_t addr) {
if ((addr & PAGEOFFMASK) != 0 || addr < PROC_START_ADDR) {
return -1;
} else if (proc_alloc(current->pid, addr, PAGESIZE)) {
return 0;
} else {
return -1;
}
}The result
Now that virtual memory is implemented, WeensyOS now looks like this:
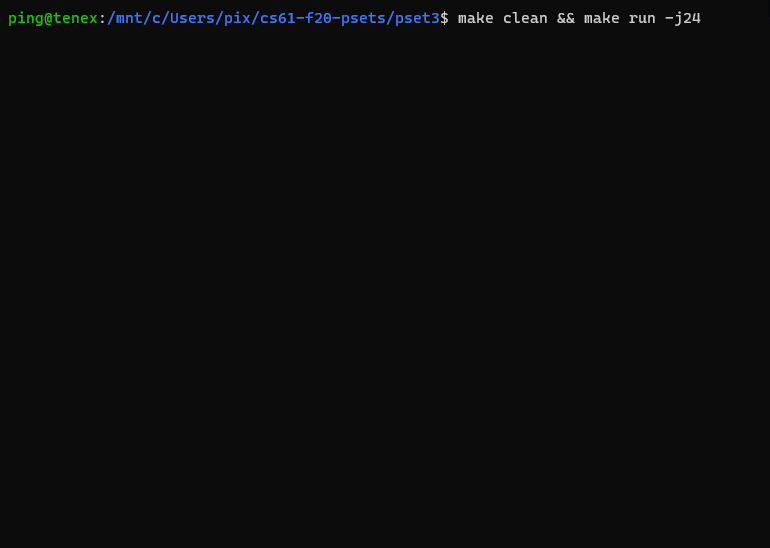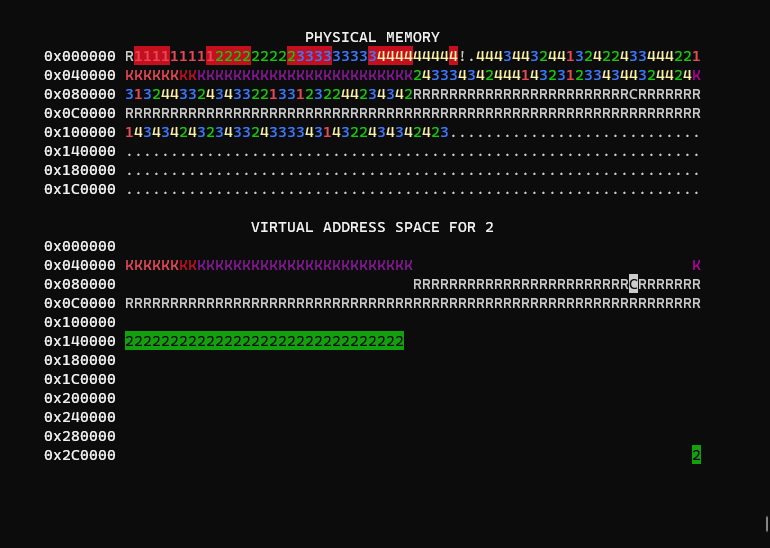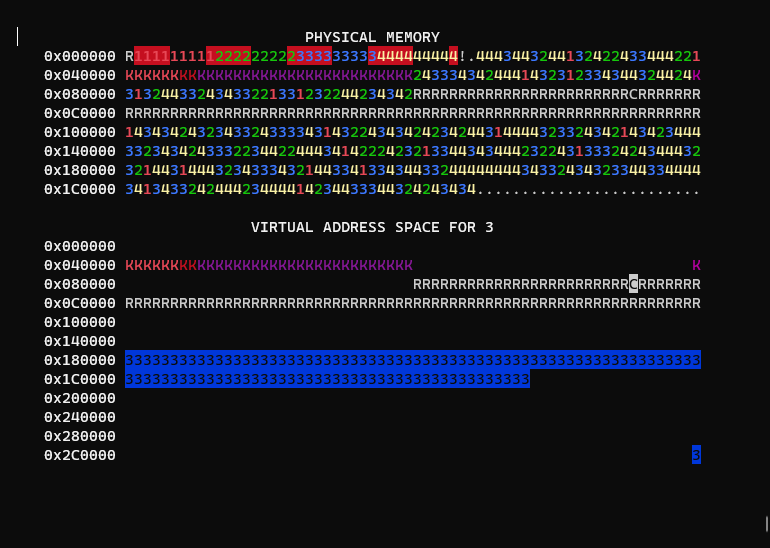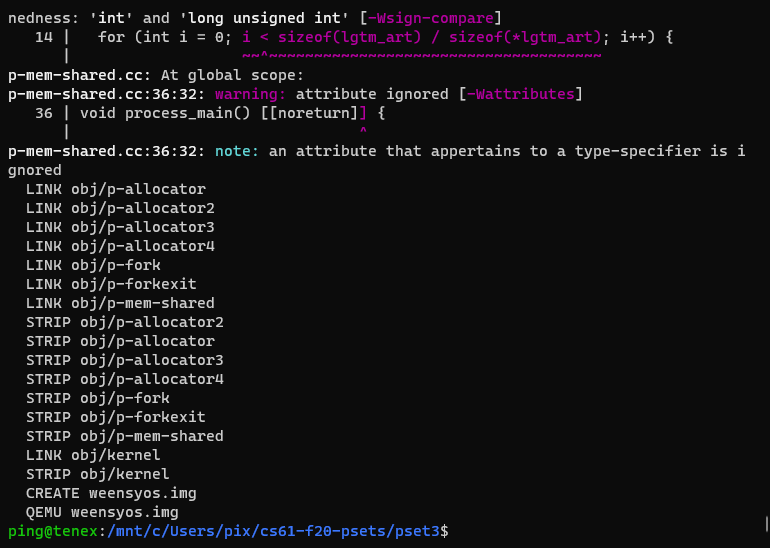
Instead of a 1:1 mapping, pages are allocated on-demand, this allows greedy processes like #4 to consume much more than PROC_SIZE bytes of memory.
Fork
The final steps of the assignment are to implement the fork syscall.
If you are not familiar with fork it essentially duplicates your process incl. its memory and execution state, for more information see the Linux fork(2).
Thankfully, all of the low level stuff is taken care of already, adding a new syscall is as simple as defining it in lib.hh and adding a switch case to exception:
uintptr_t syscall(regstate* regs) {
...
// To handle a new syscall number we just add a case here
switch (regs->reg_rax) {
...
case SYSCALL_FORK:
return syscall_fork(current);
...
}
...
}
Instead of simply copying all of the processes memory in fork, we only copy pages when they are written to. This optimization is called copy on write (COW) and can be implemented by marking a page read-only then copying it when a page fault occurs.
To tell our exception handler a page is COW, we will use one of the user-defined flags in its page table entry:
#define PTE_COW PTE_OS1 // Copy on writeThe implementation of syscall_fork goes as follows:
int syscall_fork(proc* process) {
pid_t pid = 0;
// Find the first available process id
for (pid_t i = 1; i < NPROC; i++) {
if (ptable[i].state == P_FREE) {
pid = i;
break;
}
}
if (!pid) return -1;
proc& proc_info = ptable[pid];
x86_64_pagetable* pt = kalloc_pagetable();
if (pt == nullptr) return -1;
// Copy page table of parent to child
vmiter proc_it(pt);
void* lastaquire = nullptr;
for (vmiter it(process->pagetable); it.va() < MEMSIZE_VIRTUAL; it.next()) {
int perms = it.perm();
void* kptr = it.kptr();
lastaquire = 0;
if (it.va() >= PROC_START_ADDR && it.present()) {
if (it.writable()) {
// Mark the page COW if it was writeable
perms = (it.perm() | PTE_COW) & ~PTE_W;
// Mark it COW in the parent process too, this map doesn't need to be
// reverted on abort because it does not change the semantics of writes
if (it.try_map(kptr, perms) < 0) {
goto abort_fork;
}
}
// Read-only pages will be shared implicitly, acquire a reference
kacquire(kptr);
lastaquire = kptr;
}
proc_it.find(it.va());
if (proc_it.try_map(kptr, perms) < 0) {
goto abort_fork;
}
}
// Page table creation success, initialize child process
// Copy registers from parent
proc_info.regs = process->regs;
// Set return value of child syscall to 0
proc_info.regs.reg_rax = 0;
// Enqueue the process
proc_info.wake = 0; // Field used by the sleep syscall later on
proc_info.pagetable = pt;
proc_info.state = P_RUNNABLE;
// Return child process id
return pid;
abort_fork:
// Release pa if try_map fails after an acquire or kalloc
if (lastaquire != nullptr) {
krelease(lastaquire);
}
// Release pages we've aquired so far
for (vmiter it(pt); it.va() < MEMSIZE_VIRTUAL; it += PAGESIZE) {
if (it.va() >= PROC_START_ADDR && it.present()) {
krelease(it.kptr());
}
}
free_page_table(pt);
return -1;
}In short this function copies the parent's state to a new process, remapping any writeable pages as read-only plus PTE_COW.
Now in the exception function, we can check for page faults occurring on a COW page:
void exception(regstate* regs) {
...
bool usermode = (regs->reg_cs & 0x3) != 0;
switch (regs->reg_intno) {
...
case INT_PF: {
uintptr_t addr = rdcr2();
bool is_write = regs->reg_errcode & PFERR_WRITE;
// Check if write exception was in process memory
if (usermode && is_write && addr >= PROC_START_ADDR) {
vmiter it(current->pagetable, round_down(addr, PAGESIZE));
// If page is present and PTE_OS1 is set, this is a COW page
if (it.perm() & (PTE_P | PTE_COW)) {
pageinfo& info = pages[it.pa() / PAGESIZE];
assert(info.used());
if (info.refcount == 1) {
// We have the only reference to this page, avoid copying by
// just marking it writeable
if (it.try_map(it.pa(), (it.perm() | PTE_W) & ~PTE_COW) == 0) {
// Success, resume process
break;
}
} else {
// Allocate and copy data to new page
void* kptr = kalloc();
if (kptr) {
void* source = it.kptr();
memcpy(kptr, source, PAGESIZE);
// Set writeable, clear COW
if (it.try_map(kptr, (it.perm() | PTE_W) & ~PTE_COW) == 0) {
// Success, resume process
krelease(source);
break;
}
}
}
// Out of memory!
proc_kill(current);
schedule();
}
}
// Bits that log page faults to the console
...
}
...
}
// We can quietly resume the process if not defunct
if (current->state == P_RUNNABLE) {
run(current);
} else {
schedule();
}
}The result
Along with the default program p-allocator.cc, WeensyOS also comes with p-fork.cc and p-forkexit.cc which can be booted using special key codes.
In this case we want to test the fork implementation using p-fork.cc which can be run by pressing f at startup:
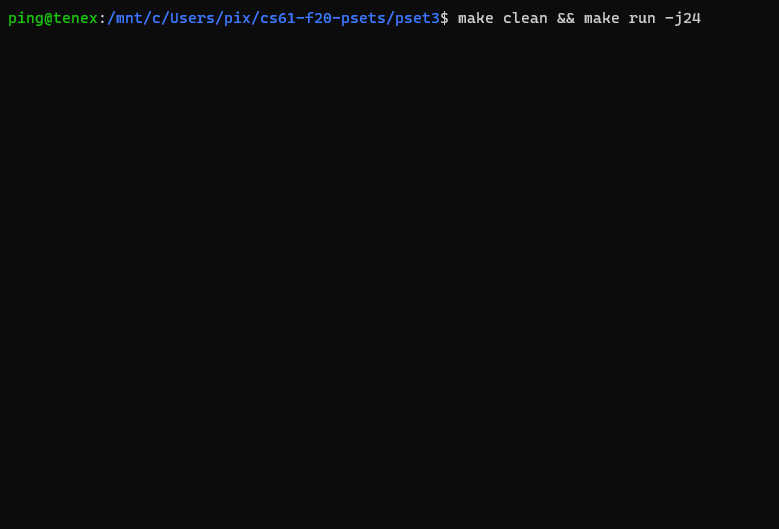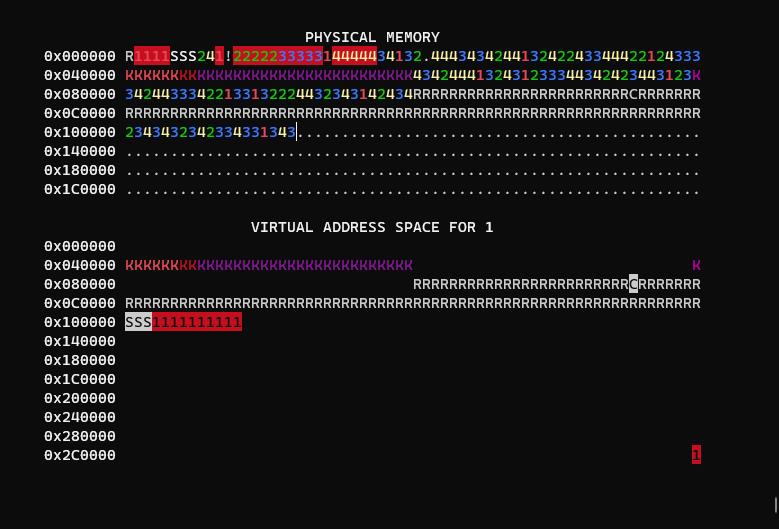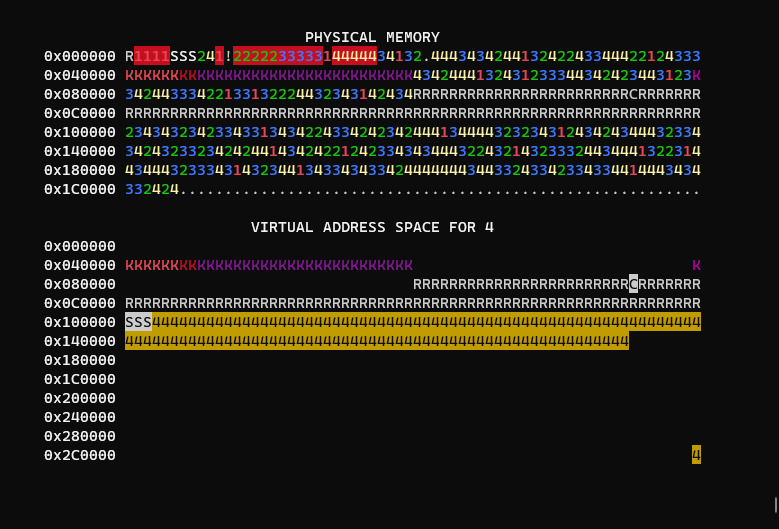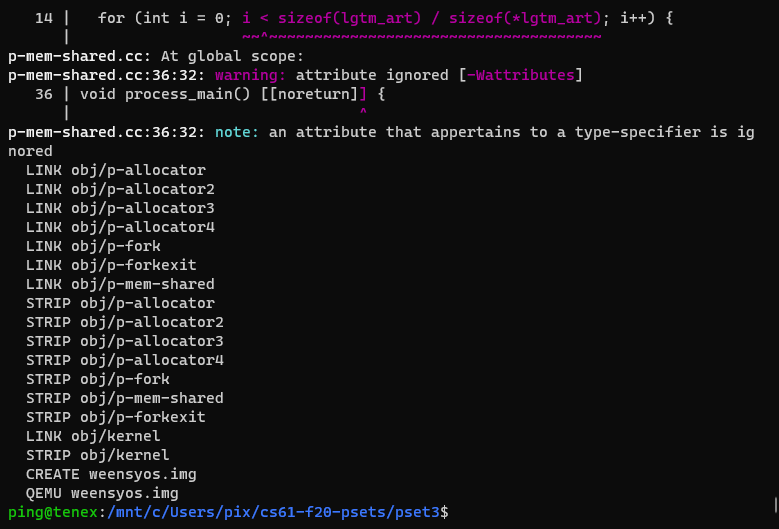
This program is a variation of the first but starts with a single process which calls fork 3 times rather than the kernel initializing them.
You may notice that the first few pages are now labelled S, this indicates the same physical address has been mapped to multiple processes.
Exit and kill
The final task of the assignment is to implement the exit syscall and test it with p-forkexit.cc. Later on we will also implement the sleep, kill, mmap, and munmap syscalls as part of extra credit.
Like with fork, you handle syscalls in the kernel by adding cases to the syscall function:
case SYSCALL_EXIT:
proc_kill(current);
schedule();
case SYSCALL_KILL:
if (arg0 > 0 && arg0 < 16 && ptable[arg0].state == P_RUNNABLE) {
proc_kill(&ptable[arg0]);
return 0;
}
return -1;Exit and kill basically do the same thing, so their functionality can just be combined into a single function.
The implementation of proc_kill turns out to be extremely simple:
// Also used in syscall_fork previously
static void free_page_table(x86_64_pagetable* pt) {
if (pt == nullptr) return;
// The ptiter utility can be used to iterate page tables recursively, as
// opposed to vmiter which just iterates virtual memory entries
for (ptiter it(pt); !it.done(); it.next()) {
kfree(it.kptr());
}
kfree(pt);
}
static void proc_kill(proc* process) {
// Clean up pages
for (vmiter it(process->pagetable); it.va() < MEMSIZE_VIRTUAL; it += PAGESIZE) {
if (it.va() >= PROC_START_ADDR && it.present()) {
krelease((void*)it.pa());
}
}
free_page_table(process->pagetable);
process->pagetable = nullptr;
process->state = P_FREE;
}p-forkexit.cc is a fairly intense test, along with consuming memory and forking it also exits at random intervals. It is quite hard to get past this point without leaking memory, there was a lot of debugging involved.
Like p-fork.cc, this program is also started through a special key combination e:
After running it for awhile we don't experience a crash and no pages are leaked!
Those large strips of Ses are COW pages that haven't been written to yet, they are shared between children just like the shared read-only segments from before.
Sleep
To implement this syscall you must first understand how the scheduler works in WeensyOS.
Here are a few notable functions we start with:
void schedule()- Picks the next runnable process and runs it.void run(proc* p)- Sets thecurrentvariable and usesexception_returnto resume the process.void exception(regstate* regs)- The exception handler called byk-exception.S, including APIC timer interrupts.
On startup kernel_start initializes the APIC timer, a neat bit of hardware that sends periodic interrupts to the processor. Along with keeping track of time with the ticks variable, this timer allows the kernel to prevent processes from hogging CPU by interrupting them.
When an interrupt or exception happens the processor will save register state, disable interrupts, enter kernel mode, and call the appropriate exception handler. The exception function copies the register state to current->regstate, which is used in the run function when resuming the process.
To resume a process the kernel uses the exception_return function, a small bit of assembly that restores register state and invokes iretq to get back into user mode.
Note that the kernel's state is not saved, you are reset back to the bottom of the stack every time there is an exception (schedule, run, and exception never return).
With this knowledge implementing sleep is much more straightforward, to start I added a field to keep track of when a specific process should resume from sleep:
struct proc {
...
unsigned long wake; // when to wake up from a sleep syscall
};Like the global ticks variable, the wake field is based on the frequency of the APIC timer (HZ), but the syscall will take its duration in milliseconds:
case SYSCALL_SLEEP:
current->regs.reg_rax = 0;
current->wake = ticks + (arg0 / (1000 / HZ));
schedule();Now rewrite the schedule function to skip any processes that are not ready to wake:
void schedule() {
for (;;) {
bool sleeping = false;
for (int i = 1; i <= NPROC; i++) {
pid_t pid = (current->pid + i) % 16;
proc& p = ptable[pid];
if (p.state != P_RUNNABLE) continue;
if (ticks >= p.wake) {
run(&p);
} else if (p.wake) {
sleeping = true;
}
}
check_keyboard();
if (sleeping) {
// Interrupts are disabled, enable them with the sti instruction
sti();
// Put the processor in a more efficient halt state while we wait
// for timer interrupts
halt();
// The halt instruction can occasionally resume, whatever, just
// disable interrupts and try again
cli();
} else {
memshow();
}
}
}Hold up, this introduces some unexpected behavior!
It turns out the exception function didn't anticipate any non-fatal exceptions to happen while in kernel mode.
The problem is that it unconditionally stashes register states to the previous process regardless of if the exception actually happened in that process. This leads to clobbering of the the state of the last running process with the state of the kernel while its halted above.
A simple solution is to only set current->regs if the lower 2 bits of the cs register (the privilege level) is non-zero:
void exception(regstate* regs) {
bool is_user_mode = (regs->reg_cs & 0x3) != 0;
if (is_user_mode) {
current->regs = *regs;
regs = ¤t->regs;
}
...
}mmap, munmap
Currently all memory management in a process is done through the very primitive sys_page_alloc syscall, this has several limitations such as:
- Can only map pages at specific address, can't find free ones automatically
- No way to free pages (munmap).
- No way to map executable or read-only pages (such as in a dynamic linker).
- No way to share memory between a parent an child process.
To solve these issues I've implemented the mmap and munmap syscalls, starting with definitions in lib.hh / u-lib.hh:
// Available flags for the sys_mmap syscall
#define MAP_PROT_READ 0x10 // Page can be read.
#define MAP_PROT_WRITE 0x20 // Page can be read and written.
#define MAP_PROT_EXEC 0x40 // Page can be executed.
#define MAP_PROT_NONE 0x00 // Page can not be accessed.
#define MAP_PRIVATE 0x00 // Changes are private.
#define MAP_SHARED 0x01 // Share changes.
#define MAP_FIXED 0x02 // Interpret addr exactly.Note that MAP_ANONYMOUS is not defined because there is no filesystem, all mappings are anonymous by default!
inline void* sys_mmap(void* addr, size_t length, int flags) {
return (void*)make_syscall(SYSCALL_MMAP, (uintptr_t)addr, length, flags);
}
inline int sys_munmap(void* addr, size_t length) {
return make_syscall(SYSCALL_MUNMAP, (uintptr_t)addr, length);
}
// Replace previous implementation with one that uses mmap
inline int sys_page_alloc(void* addr) {
void* result = sys_mmap(addr, PAGESIZE, MAP_PRIVATE | MAP_FIXED | MAP_PROT_WRITE);
return result == nullptr ? -1 : 0;
}
inline int sys_page_free(void* addr) {
return sys_munmap(addr, PAGESIZE);
}Like other syscalls, mmap and munmap get their own functions:
case SYSCALL_MMAP:
return syscall_mmap(current, arg0, arg1, arg2);
case SYSCALL_MUNMAP:
return syscall_munmap(current, arg0, arg1);The syscall_mmap function is probably the most complex so far as it has to handle several edge cases and failure conditions, its implementation goes as follows:
static uintptr_t next_free_vaddr(proc* process, uintptr_t num_pages) {
// This could be made a lot faster if we used a tree to manage virtual
// address space.
size_t viable = 0;
vmiter it(process->pagetable);
for (uintptr_t addr = PROC_START_ADDR; addr < MEMSIZE_VIRTUAL; addr += PAGESIZE) {
it.find(addr);
if (it.present()) {
viable = 0;
} else if (++viable == num_pages) {
// Found free pages
addr -= (viable - 1) * PAGESIZE;
return addr;
}
}
return 0;
}
static uintptr_t syscall_mmap(proc* process, uint64_t addr, uint64_t length, uint64_t flags) {
if ((addr & PAGEOFFMASK) != 0 || length == 0) {
// The base address must be a multiple of PAGESIZE
return 0;
}
uintptr_t num_pages = (length + PAGESIZE - 1) / PAGESIZE;
vmiter it(process->pagetable);
if (addr == 0) {
// nullptr always allocates new pages
addr = next_free_vaddr(process, num_pages);
} else if ((flags & MAP_FIXED) == 0) {
// If the address is not fixed, reallocate if any overlap with existing maps
for (uintptr_t i = 0; i < num_pages; i++) {
it.find(addr + i * PAGESIZE);
if (it.present()) {
// Page overlaps, reallocate
addr = next_free_vaddr(process, num_pages);
break;
}
}
}
uintptr_t end = addr + num_pages * PAGESIZE;
if (
addr < PROC_START_ADDR
|| end > MEMSIZE_VIRTUAL
|| num_pages > PAGESIZE / sizeof(uint64_t)
) {
// Either the range is invalid, we failed to allocate one, or there are too
// many page entries to fit in a journal.
return 0;
}
uint64_t pte = PTE_PXD;
if (flags & MAP_SHARED) pte |= PTE_SHARED;
if (flags & MAP_PROT_READ) pte |= PTE_PU;
if (flags & MAP_PROT_WRITE) pte |= PTE_PWU;
if (flags & MAP_PROT_EXEC) pte &= ~PTE_XD;
// Keep a journal of the entries that we clobber, so they can be restored on failure
auto journal = (uint64_t*)kalloc();
if (journal == nullptr) {
return 0;
}
for (uintptr_t i = 0; i < num_pages; i++) {
it.find(addr + i * PAGESIZE);
uint64_t pa = it.pa();
uint64_t perm = it.perm();
journal[i] = perm | pa;
uint64_t new_perm = pte;
if (!(perm & PTE_P)) {
// Allocate new pages if they do not exist
pa = (uint64_t)kalloc();
if (pa == 0) {
goto abort_map;
}
} else if (pages[pa / PAGESIZE].refcount > 1 && (new_perm & PTE_PWU)) {
// If page has multiple references and should be writable, mark it COW
new_perm = (new_perm & ~PTE_W) | PTE_COW;
}
// Finally apply permissions
if (it.try_map(pa, new_perm) < 0) {
if (!it.present()) {
kfree((void*)pa);
}
goto abort_map;
}
continue;
abort_map:
// Map incomplete, revert changes using journal
for (uintptr_t p = 0; p < i; p++) {
it.find(addr + p * PAGESIZE);
uint64_t prev = journal[i];
if (!(prev & PTE_P)) {
kfree(it.kptr());
}
it.map(prev & PTE_PAMASK, prev & ~PTE_PAMASK);
}
kfree(journal);
return 0;
}
// Success, all pages have been mapped
kfree(journal);
return addr;
}Because try_map / kalloc can fail at any point, the implementation of mmap writes exiting page table entries to a journal that can be rolled back.
A similar is approach is used to release pages with munmap:
static int syscall_munmap(proc* process, uint64_t addr, uint64_t length) {
if ((addr & PAGEOFFMASK) != 0 || length == 0) {
// The base address must be a multiple of PAGESIZE
return 0;
}
uintptr_t num_pages = (length + PAGESIZE - 1) / PAGESIZE;
vmiter it(process->pagetable);
uintptr_t end = addr + length;
if ((length == 0 || addr < PROC_START_ADDR || end > MEMSIZE_VIRTUAL || addr > end)) {
return 0;
}
// Keep a journal of the entries that we clobber
auto journal = (uint64_t*)kalloc();
assert(num_pages <= PAGESIZE / sizeof(uint64_t));
if (journal == nullptr) {
return -1;
}
for (uintptr_t i = 0; i < num_pages; i++) {
it.find(addr + i * PAGESIZE);
uint64_t pa = it.pa();
journal[i] = it.perm() | pa;
// Finally apply permissions
if (it.try_map(pa, 0) < 0) {
// Mapping incomplete, revert changes using journal
for (uintptr_t p = 0; p < i; p++) {
it.find(addr + p * PAGESIZE);
uint64_t prev = journal[i];
it.map(prev & PTE_PAMASK, prev & ~PTE_PAMASK);
}
kfree(journal);
return -1;
}
}
// Success, all pages have been mapped, release their references.
for (uintptr_t i = 0; i < num_pages; i++) {
if (journal[i] & PTE_P) {
kfree((void*)(journal[i] & PTE_PAMASK));
}
}
kfree(journal);
return 0;
}Testing all the things
In order to test all the new syscalls we need to create custom user-mode programs, thankfully the process is pretty straightforward.
First, create the program:
#include "u-lib.hh"
[[noreturn]] void process_main() {
// Let the system allocate new memory, make it shared between procs
int* shared_memory = (int*)sys_mmap(nullptr, PAGESIZE, MAP_SHARED | MAP_PROT_WRITE);
assert(shared_memory != nullptr);
pid_t cp = sys_fork();
if (cp == 0) {
// Child process
// Read 1, write 2, wait
assert_eq(*shared_memory, 1);
*shared_memory = 2;
sys_sleep(1000);
// Read 3
assert_eq(*shared_memory, 3);
// Write 4 until killed
for (;;) {
*shared_memory = 4;
sys_yield();
}
} else {
// Parent process
// Write 1, wait
*shared_memory = 1;
sys_sleep(500);
// Read 2, write 3, wait
assert_eq(*shared_memory, 2);
*shared_memory = 3;
sys_sleep(1000);
// Read 4
assert_eq(*shared_memory, 4);
// Kill, write 5, wait
sys_kill(cp);
*shared_memory = 5;
sys_sleep(1000);
// Read 5
assert_eq(*shared_memory, 5);
// Success
sys_munmap(shared_memory, PAGESIZE);
panic("Success!");
}
}
This test covers most of the functionality of mmap, sleep, kill, munmap, then panics with a success message after everything checks out.
Next, add the program to the Makefile:
PROCESS_BINARIES += $(OBJDIR)/p-custom
PROCESS_OBJS += $(OBJDIR)/p-custom.uoFinally, add it to k-hardware.cc:
// These symbols are defined by the linker
extern uint8_t _binary_obj_p_custom_start[];
extern uint8_t _binary_obj_p_custom_end[];
...
} ramimages[] = {
...
{"custom", _binary_obj_p_custom_start, _binary_obj_p_custom_end}};
// The ramimages table defines ranges of static memory for
// each process binary
...
int check_keyboard() {
...
// Add custom key codes here and below
if (c == 'a' || c == 'f' || c == 'e' || c == 'c') {
...
// The kernel uses this argument to load a specific program
// from the table above
const char* argument = "fork";
if (c == 'a') {
...
} else if (c == 'c') {
argument = "custom";
}
...
}
...
}Now the program should run when you press c:

Success!
